I’ve had an unusual number of interesting conversations spin out of my previous article documenting that mobile web apps are slow. This has sparked some discussion, both online and IRL. But sadly, the discussion has not been as… fact-based as I would like.
So what I’m going to do in this post is try to bring some actual evidence to bear on the problem, instead of just doing the shouting match thing. You’ll see benchmarks, you’ll hear from experts, you’ll even read honest-to-God journal papers on point. There are–and this is not a joke–over 100 citations in this blog post. I’m not going to guarantee that this article will convince you, nor even that absolutely everything in here is totally correct–it’s impossible to do in an article this size–but I can guarantee this is the most complete and comprehensive treatment of the idea that many iOS developers have–that mobile web apps are slow and will continue to be slow for the forseeable future.
Now I am going to warn you–this is a very freaking long article, weighing in at very nearly 10k words. That is by design. I have recently come out in favor of articles that are good over articles that are popular. This is my attempt at the former, and my attempt to practice what I have previously preached: that we should incentivize good, evidence-based, interesting discussion and discourage writing witty comments.
I write in part because this topic has been discussed–endlessly–in soundbyte form. This is not Yet Another Bikeshed Article, so if you are looking for that 30-second buzz of “no really, web apps suck!” vs “No they don’t!” this is not the article for you. (Go read one of these oh no make it stop can’t breathe not HN too I can’t do this anymore please just stop so many opinions so few facts I can go on). On the other hand, as best as I can tell, there is no comprehensive, informed, reasonable discussion of this topic happening anywhere. It may prove to be a very stupid idea, but this article is my attempt to talk reasonably about a topic that has so far spawned 100% unreasonable flamewar-filled bikeshed discussions. In my defense, I have chosen to believe the problem has more to do with people who can discuss better and simply don’t, than anything to do with the subject matter. I suppose we’ll find out.
So if you are trying to figure out exactly what brand of crazy all your native developer friends are on for continuing to write the evil native applications on the cusp of the open web revolution, or whatever, then bookmark this page, make yourself a cup of coffee, clear an afternoon, find a comfy chair, and then we’ll both be ready.
A quick review
My previous blog post documented, based on SunSpider benchmarks, that the state of the world, today, is that mobile web apps are slow.
Now, if what you mean by “web app” is “website with a button or two”, you can tell all the fancypants benchmarks like SunSpider to take a hike. But if you mean “light word processing, light photo editing, local storage, and animations between screens” then you don’t want to be doing that in a web app on ARM unless you have a death wish.
You should really go read that article, but I will show you the benchmark anyway: 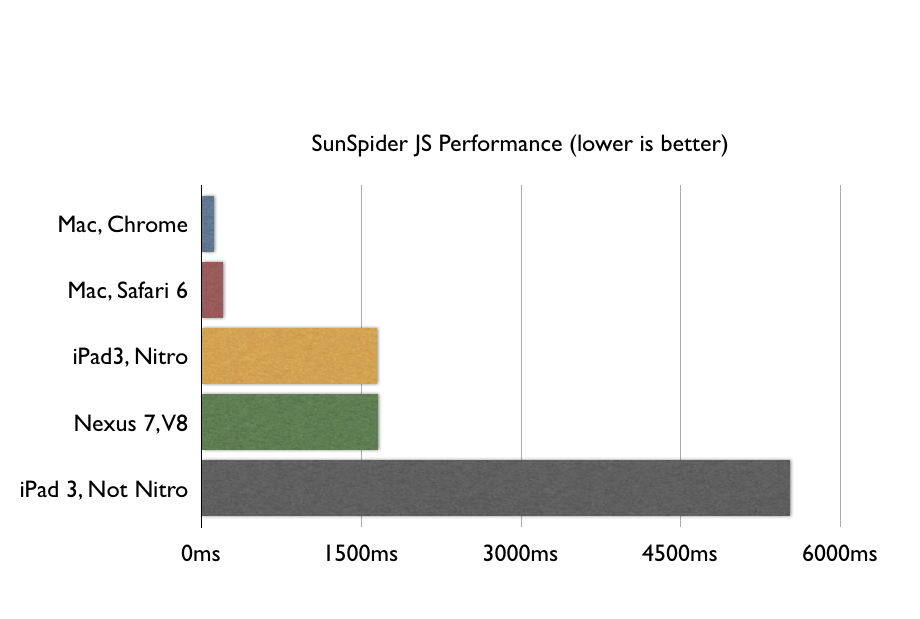
Essentially there are three categories of criticism about this benchmark:
- The fact that JS is slower than native code is not news: everybody learned this in CS1 when they talked about compiled vs JIT vs interpreted languages. The question is whether it is appreciably slower in some way that actually matters for the kind of software you are writing, and benchmarks like these fail to address that problem one way or the other.
- Yes JS is slower and yes it matters, but it keeps getting faster and so one day soon we will find ourselves in case #1 where it is no longer appreciably slower, so start investing in JS now.
- I write Python/PHP/Ruby server-side code and I have no idea what you guys keep going on about. I know that my servers are faster than your mobile devices, but surely if I am pretty comfortable supporting X,000 users using an actually interpreted language, you guys can figure out how to support a single user in a language with a high-performance JIT? How hard can it be?
I have the rather lofty goal of refuting all three claims in this article: yes, JS is slow in a way that actually matters, no, it will not get appreciably faster in the near future, and no, your experience with server-side programming does not adequately prepare you to “think small” and correctly reason about mobile performance.
But the real elephant in the room here is that in all these articles on this subject, rarely does anyone actually quantify how slow JS is or provide any sort of actually useful standard of comparison. (You know… slow relative to what?) To correct this, I will develop, in this article, not just one useful equivalency for JavaScript performance–but three of them. So I’m not only going to argue the “traditional hymns” of “wa wa JS is slow for arbitrary case”, but I’m going to quantify exactly how slow it is, and compare it to a wide variety of things in your real-life programming experience so that, when you are faced with your own platform decision, you can do your own back-of-the-napkin math on whether or not JavaScript is feasible for solving your own particular problem.
Okay, but how does JS performance compare to native performance exactly?
It’s a good question. To answer it, I grabbed an arbitrary benchmark from The Benchmarks Game. I then found an older C program that does the same benchmark (older since the newer ones have a lot of x86-specific intrinsics). Then benchmarked Nitro against LLVM on my trusty iPhone 4S. All the code is up on GitHub.
Now this is all very arbitrary–but the code you’re running in real life is equally arbitrary. If you want a better experiment, go run one. This is just the experiment I ran, because there aren’t any other experiments that compare LLVM to Nitro that exist.
Anyway, in this synthetic benchmark, LLVM is consistently 4.5x faster than Nitro:
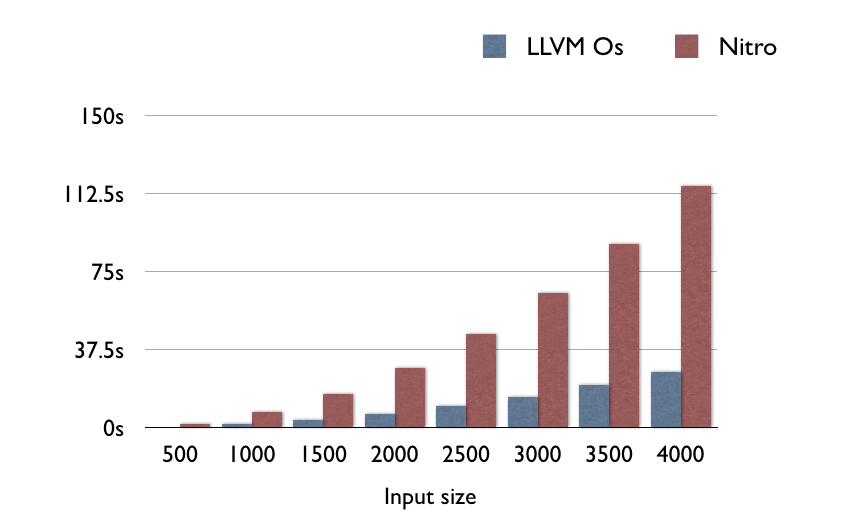
So if you are wondering “How much faster is my CPU-bound function in native code instead of Nitro JS” the answer is about 5x faster. This result is roughly consistent with the Benchmarks Game’s results with x86/GCC/V8. They claim that GCC/x86 is generally between 2x and 9x faster than V8/x86. So the result seems in the right ballpark, and also seems consistent no matter if you are on ARM or x86.
But isn’t 1/5 performance good enough for anyone?
It’s good enough on x86. How CPU-intensive is rendering a spreadsheet, really? It’s not really that hard. Problem is, ARM isn’t x86.
According to GeekBench, the latest MBP against the latest iPhone is a full factor of 10 apart. So that’s okay–spreadsheets really aren’t that hard. We can live with 10% performance. But then you want to divide that by five? Woah there buddy. Now we’re down to 2% of desktop performance. (I’m playing fast-and-loose with the units, but we’re dealing with orders of magnitude here. Close enough.)
Okay, but how hard is word processing, really? Couldn’t we do it on like an m68k with one coprocessor tied behind its back? Well, this is an answerable question. You may not recall, but Google Docs’ realtime collaboration was not, in fact, a launch feature. They did a massive rewrite that added it in April 2010. Let’s see what browser performance looked like in 2010. ![BrowserCompChart1 9-6-10[7]](../../../wp-content/uploads/2013/05/BrowserCompChart1-9-6-107.png)
What should be plainly obvious from this chart is that the iPhone 4S is not at all competitive with web browsers around the time that Google Docs did real-time collaboration. Well, it’s competitive with IE8. Congratulations on that.
Let’s look at another serious JavaScript application: Google Wave. Wave never supported IE8–according to Google–because it was too slow.
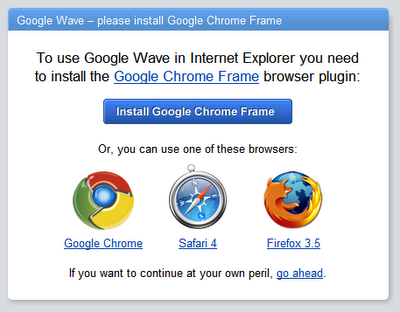
Notice how all these browsers bench faster than the iPhone 4S?
Notice how all the supported browsers bench below 1000, and the one that scores 3800 is excluded for being too slow? The iPhone benches 2400. It, just like IE8, isn’t fast enough to run Wave.
Just to be clear: is possible to do real-time collaboration on on a mobile device. It just isn’t possible to do it in JavaScript. The performance gap between native and web apps is comparable to the performance gap between FireFox and IE8, which is too large a gap for serious work.
But I thought V8 / modern JS had near-C performance?
It depends on what you mean by “near”. If your C program executes in 10ms, then a 50ms JavaScript program would be “near-C” speed. If your C program executes in 10 seconds, a 50-second JavaScript program, for most ordinary people would probably not be near-C speed.
The hardware angle
But a factor of 5 is okay on x86, because x86 is ten times faster than ARM just to start with. You have a lot of headroom. The solution is obviously just to make ARM 10x faster, so it is competitive with x86, and then we can get desktop JS performance without doing any work!
Whether or not this works out kind of hinges on your faith in Moore’s Law in the face of trying to power a chip on a 3-ounce battery. I am not a hardware engineer, but I once worked for a major semiconductor company, and the people there tell me that these days performance is mostly a function of your process (e.g., the thing they measure in “nanometers”). The iPhone 5’s impressive performance is due in no small part to a process shrink from 45nm to 32nm — a reduction of about a third. But to do it again, Apple would have to shrink to a 22nm process.
Just for reference, Intel’s Bay Trail–the x86 Atom version of 22nm–doesn’t currently exist. And Intel had to invent a whole new kind of transistor since the ordinary kind doesn’t work at 22nm scale. Think they’ll license it to ARM? Think again. There are only a handful of 22nm fabs that people are even seriously thinking about building in the world, and most of them are controlled by Intel.
In fact, ARM seems on track to do a 28nm process shrink in the next year or so (watch the A7), and meanwhile Intel is on track to do 22nm and maybe even 20nm just a little further out. On purely a hardware level, it seems much more likely to me that an x86 chip with x86-class performance will be put in a smartphone long before an ARM chip with x86-class performance can be shrunk.
Update from an ex-Intel engineer who e-mailed me:
I’m an ex-Intel engineer, worked on the mobile microprocessor line and later on the Atoms. For what it’s worth, my incredibly biased opinion is that it’s going to be easier for x86 to get into a phone envelope with the “feature toolbox” from the larger cores than it will be for ARM to grow up to x86 performance levels designing such features from scratch.
Update from a robotics engineer who e-mailed me:
You are perfectly right that these will not bring ultra major performance boost and that Intel may have a higher performing mobile CPU a few years from now. In fact, mobile CPUs is currently hitting the same type of limit that desktop CPUs hit when they reached ~3GHz : Increasing clock speed further is not feasible without increasing power a lot, same will be true for next process nodes although they should be able to increase IPC a bit (10-20% maybe). When they faced that limit, desktop CPUs started to become dual and quad cores, but mobile SoC are already dual and quad so there is no easy boost.
So Moore’s Law might be right after all, but it is right in a way that would require the entire mobile ecosystem to transition to x86. It’s not entirely impossible–it’s been done once before. But it was done at a time when yearly sales were around a million units, and now they are selling 62 million per quarter. It was done with an off-the-shelf virtualization environment that could emulate the old architecture at about 60% speed, meanwhile the performance of today’s hypothetical research virtualization systems for optimized (O3) ARM code are closer to 27%.
If you believe JavaScript performance is going to get there eventually, really the hardware path is the best path. Either Intel will have a viable iPhone chip in 5 years (likely) and Apple will switch (unlikely), or perhaps ARM will sort themselves out over the next decade. (Go talk to 10 hardware engineers to get 10 opinions on the viability of that.) But a decade is a long time, from my chair, for something that might pan out.
I’m afraid my knowledge of the hardware side runs out here. What I can tell you is this: if you want to believe that ARM will close the gap with x86 in the next 5 years, the first step is to find somebody who works on ARM or x86 (e.g., the sort of person who would actually know) to agree with you. I have consulted many such qualified engineers for this article, and they have all declined to take the position on record. This suggests to me that the position is not any good.
The software angle
Here is where a lot of competent software engineers stumble. The thought process goes like this–JavaScript has gotten faster! It will continue to get faster!
The first part is true. JavaScript has gotten a lot faster. But we’re now at Peak JavaScript. It doesn’t get much faster from here.
Why? Well the first part is that most of the improvements to JavaScript over its history have actually been of the hardware sort. Jeff Atwood writes:
I found that the performance of JavaScript improved a hundredfold between 1996 and 2006. If Web 2.0 is built on a backbone of JavaScript, it’s largely possible only because of those crucial Moore’s Law performance improvements.
If we attribute JS’s speedup to hardware generally, JS’s (hardware) performance improvement does not predict future software improvement. This is why, if you want to believe that JS is going to get faster, by far the most likely way is by the hardware getting faster, because that is what the historical trend says.
What about JITs though? V8, Nitro/SFX, TraceMonkey/IonMonkey, Chakra, and the rest? Well, they were kind of a big deal when they came out–although not as big of a deal as you might think. V8 was released in September 2008. I dug up a copy of Firefox 3.0.3 from around the same time:
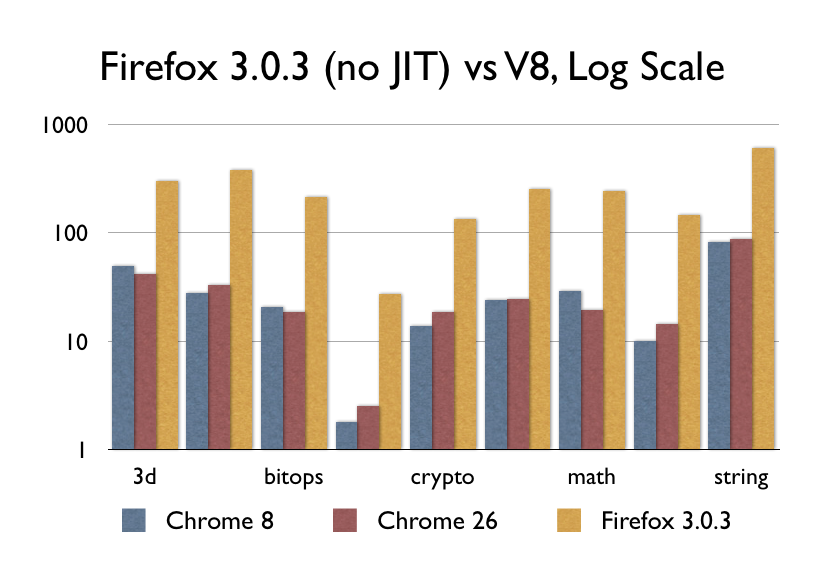
Don’t get me wrong, a 9x improvement in performance is nothing to sneeze at–after all, it’s nearly the difference between ARM and x86. That said, the performance between Chrome 8 and Chrome 26 is a flatline, because nothing terribly important has happened since 2008. The other browser vendors have caught up–some slower, some faster–but nobody has really improved the speed of actual CPU code since.
Is JavaScript improving?
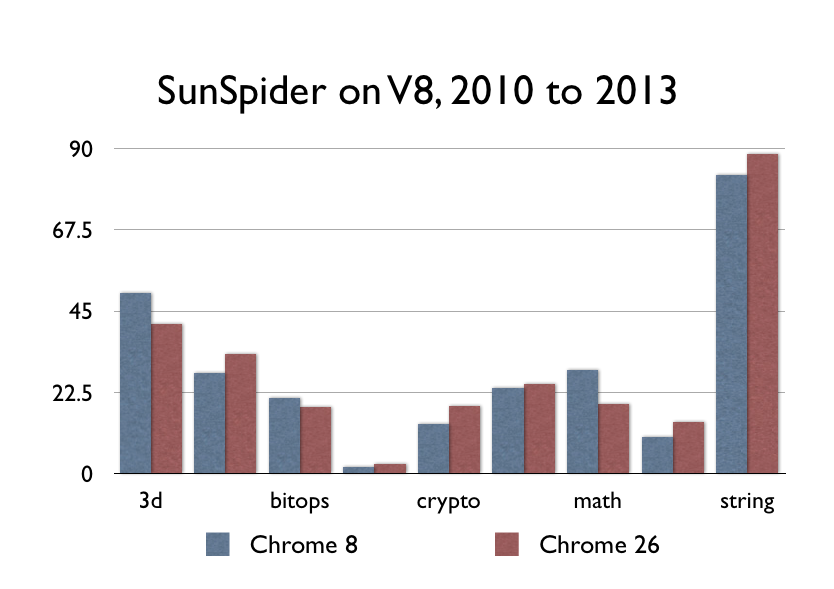
Here’s Chrome v8 on my Mac (the earliest one that still ran, Dec 2010.) Now here’s v26.
Can’t spot the difference? That’s because there isn’t one. Nothing terribly important has happened to CPU-bound JavaScript lately.
If the web feels faster to you than it did in 2010, that is probably because you’re running a faster computer, but it has nothing to do with improvements to Chrome.
Update Some smart people have pointed out that SunSpider isn’t a good benchmark these days (but have declined to provide any actual numbers or anything). In the interests of having a reasonable conversation, I ran Octane (a Google benchmark) on some old versions of Chrome, and it does show some improvement:
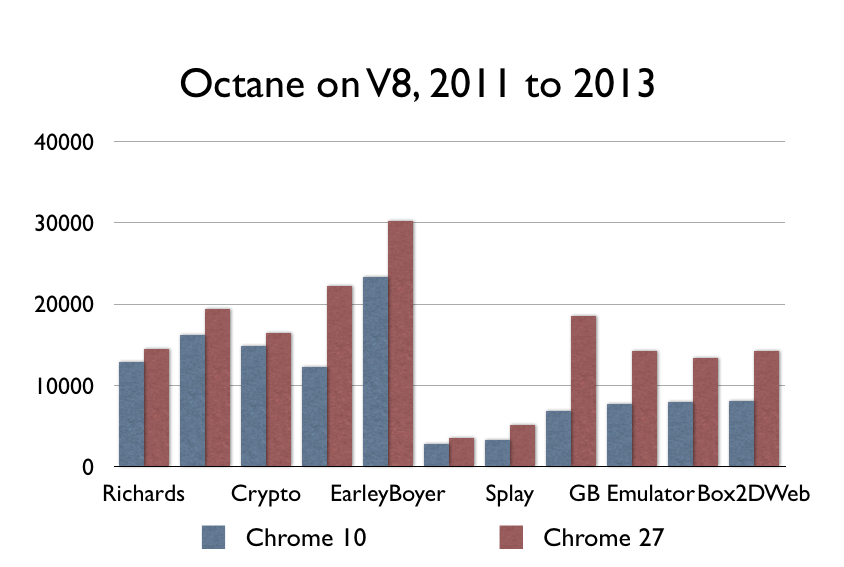
In my opinion, this magnitude of performance gain over this period is much too small to support the claim that JS will close the gap in any reasonable amount of time. However, I think it’s fair to say that I overstated the case a bit–something is happening in CPU-bound JavaScript. But to me, these numbers confirm the larger hypothesis: these gains are not the order-of-magnitude that will close the gap with native code, in any reasonable amount of time. You need to get to 2x-9x across the board to compete with LLVM. These improvements are good, but they’re not that good. End update
The thing is, JITing JavaScript was a 60-year old idea with 60 years of research, and literally thousands of implementations for every conceivable programming language demonstrating that it was a good idea. But now that we’ve done it, we’ve run out of 60-year-old ideas. That’s all, folks. Show’s over. Maybe we can grow another good idea in the next 60 years.
But Safari is supposedly faster than before?
But if this is all true, how come we keep hearing about all the great performance improvements in JavaScript? It seems every other week, somebody is touting huge speedups in some benchmark. Here is Apple claiming a staggering 3.8x speedup on JSBench:
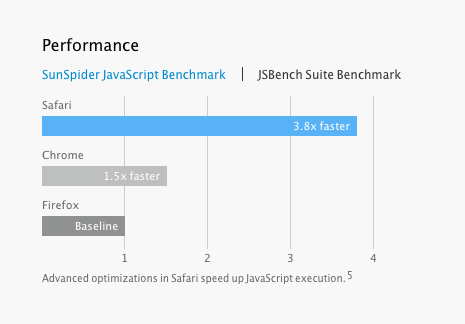
]56 Is Safari 7 3.8x faster than the other guys?
Perhaps conveniently for Apple, this version of Safari is currently under NDA, so nobody is able to publish independent numbers on Safari performance one way or the other. But let me make some observations on this kind of claim that’s purely on the basis of publicly available information.
I find it interesting, first, that Apple’s public claims on JSBench are much higher than their claims for traditional benchmarks like SunSpider. Now JSBench has some cool names behind it including Brenden Eich, the creator of JavaScript. But unlike traditional benchmarks, the way JSBench works isn’t by writing a program that factors integers or something. Instead, JSBench automatically scrapes whatever Amazon, Facebook, and Twitter serve up, and builds benchmarks out of that. If you are writing a web browser that (let’s be honest) most people use to browse Facebook, I can see how having a benchmark that’s literally Facebook is very useful. On the other hand, if you are writing a spreadsheet program, or a game, or an image filter application, it seems to me that a traditional benchmark with e.g. integer arithmetic and md5 hashing is going to be much more predictive for you than seeing how fast Facebook’s analytics code can run.
The other important fact is that an improvement on SunSpider, as Apple claims, does not necessarily mean anything else improves. In the very paper that introduces Apple’s preferred benchmark, Eich et al write the following:
The graph clearly shows that, according to SunSpider, the performance of Firefox improved over 13× between version 1.5 and version 3.6. Yet when we look at the performance improvements on amazon they are a more modest 3×. And even more interestingly, in the last two years, gains on amazon have flattened. Suggesting that some of the optimizations that work well on Sun Spider do little for amazon. [sic]
In this very paper, the creator of JavaScript and one of the top architects for Mozilla openly admits that nothing at all has happened to the performance of Amazon’s JavaScript in two years, and nothing terribly exciting has ever happened. This is your clue that the marketing guys have oversold things just a bit over the years.
(They go on to argue, essentially, that benchmarking Amazon is a better predictor for running Amazon than benchmarking SunSpider [uh… obvious…], and is therefore good to do for web browsers which people use to visit Amazon. But none of this will help you write a photo processing application.)
But at any rate, what I can tell you, from publicly available information, is that Apple’s claims of 3.8x faster whatever does not necessarily translate into anything useful to you. I can also tell you that if I had benchmarks that refuted Apple’s claims of beating Chrome, I would not be allowed to publish them.
So let’s just conclude this section by saying that just because somebody has a bar chart that shows their web browser is faster does not necessarily mean JS as a whole is getting any faster.
But there is a bigger problem.
Not designed for performance

This is from Herb Sutter, one of the big names in modern C++:
This is a 199x/200x meme that’s hard to kill – “just wait for the next generation of (JIT or static) compilers and then managed languages will be as efficient.” Yes, I fully expect C# and Java compilers to keep improving – both JIT and NGEN-like static compilers. But no, they won’t erase the efficiency difference with native code, for two reasons. First, JIT compilation isn’t the main issue. The root cause is much more fundamental: Managed languages made deliberate design tradeoffs to optimize for programmer productivity even when that was fundamentally in tension with, and at the expense of, performance efficiency… In particular, managed languages chose to incur costs even for programs that don’t need or use a given feature; the major examples are assumption/reliance on always-on or default-on garbage collection, a virtual machine runtime, and metadata. But there are other examples; for instance, managed apps are built around virtual functions as the default, whereas C++ apps are built around inlined functions as the default, and an ounce of inlining prevention is worth a pound of devirtualization optimization cure.
This quote was endorsed by Miguel de Icaza of Mono, who is on the very short list of “people who maintain a major JIT compiler”. He said:
This is a pretty accurate statement on the difference of the mainstream VMs for managed languages (.NET, Java and Javascript). Designers of managed languages have chosen the path of safety over performance for their designs.
Or, you could talk to Alex Gaynor, who maintains an optimizing JIT for Ruby and contributes to the optimizing JIT for Python:
It’s the curse of these really high-productivity dynamic languages. They make creating hash tables incredibly easy. And that’s an incredibly good thing, because I think C programmers probably underuse hash tables, because they’re a pain. For one you don’t have one built in. For two, when you try to use one, you just hit pain left and right. By contrast, Python, Ruby, JavaScript people, we overuse hashtables because they’re so easy… And as a result, people don’t care…
Google seems to think that JavaScript is facing a performance wall:
Complex web apps–the kind that Google specializes in–are struggling against the platform and working with a language that cannot be tooled and has inherent performance problems.
Lastly, hear it from the horse’s mouth. One of my readers pointed me to this comment by Brendan Eich. You know, the guy who invented JavaScript.
One thing Mike didn’t highlight: get a simpler language. Lua is much simpler than JS. This means you can make a simple interpreter that runs fast enough to be balanced with respect to the trace-JITted code [unlike with JS].
and a little further down:
On the differences between JS and Lua, you can say it’s all a matter of proper design and engineering (what isn’t?), but intrinsic complexity differences in degree still cost. You can push the hard cases off the hot paths, certainly, but they take their toll. JS has more and harder hard cases than Lua. One example: Lua (without explicit metatable usage) has nothing like JS’s prototype object chain.
Of the people who actually do relevant work: the view that JS in particular, or dynamic languages in general, will catch up with C, is very much the minority view. There are a few stragglers here and there, and there is also no real consensus what to do about it, or if anything should be done about it at all. But as to the question of whether, from a language perspective, in general, the JITs will catch up–the answer from the people working on them is “no, not without changing either the language or the APIs.”
But there is an even bigger problem.
All about garbage collectors

You see, the CPU problem, and all the CPU-bound benchmarks, and all the CPU-bound design decisions–that’s really only half the story. The other half is memory. And it turns out, the memory problem is so vast, that the whole CPU question is just the tip of the iceberg. In fact, arguably, that entire CPU discussion is a red herring. What you are about to read should change the whole way you think about mobile software development.
In 2012, Apple did a curious thing (well, unless you are John Gruber and saw it coming). They pulled garbage collection out of OSX. Seriously, go read the programming guide. It has a big fat “(Not Recommended)” right in the title. If you come from Ruby, or Python, or JavaScript, or Java, or C#, or really any language since the 1990s, this should strike you as really odd. But it probably doesn’t affect you, because you probably don’t write ObjC for Mac, so meh, click the next link on HN. But still, it seems strange. After all, GC has been around, it’s been proven. Why in the world would you deprecate it? Here’s what Apple had to say:
We feel so strongly about ARC being the right approach to memory management that we have decided to deprecate Garbage Collection in OSX. – Session 101, Platforms Kickoff, 2012, ~01:13:50
The part that the transcript doesn’t tell you is that the audience broke out into applause upon hearing this statement. Okay, now this is really freaking weird. You mean to tell me that there’s a room full of developers applauding the return to the pre-garbage collection chaos? Just imagine the pin drop if Matz announced the deprecation of GC at RubyConf. And these guys are happy about it? Weirdos.
Rather than write off the Apple fanboys as a cult, this very odd reaction should clue you in that there is more going on here than meets the eye. And this “more going on” bit is the subject of our next line of inquiry.
So the thought process goes like this: Pulling a working garbage collector out of a language is totally crazy, amirite? One simple explanation is that perhaps ARC is just a special Apple marketing term for a fancypants kind of garbage collector, and so what these developers are, in fact applauding–is an upgrade rather than a downgrade. In fact, this is a belief that a lot of iOS noobs have.
ARC is not a garbage collector
So to all the people who think ARC is some kind of garbage collector, I just want to beat your face in with the following Apple slide:

This has nothing to do with the similarly-named garbage collection algorithm. It isn’t GC, it isn’t anything like GC, it performs nothing like GC, it does not have the power of GC, it does not break retain cycles, it does not sweep anything, it does not scan anything. Period, end of story, not garbage collection.
The myth somehow grew legs when a lot of the documentation was under NDA (but the spec was available, so that’s no excuse) and as a result the blogosphere has widely reported it to be true. It’s not. Just stop.
GC is not as feasible as your experience leads you to believe
So here’s what Apple has to say about ARC vs GC, when pressed:
At the top of your wishlist of things we could do for you is bringing garbage collection to iOS. And that is exactly what we are not going to do… Unfortunately garbage collection has a suboptimal impact on performance. Garbage can build up in your applications and increase the high water mark of your memory usage. And the collector tends to kick in at undeterministic times which can lead to very high CPU usage and stutters in the user experience. And that’s why GC has not been acceptable to us on our mobile platforms. In comparison, manual memory management with retain/release is harder to learn, and quite frankly it’s a bit of a pain in the ass. But it produces better and more predictable performance, and that’s why we have chosen it as the basis of our memory management strategy. Because out there in the real world, high performance and stutter-free user experiences are what matters to our users. ~Session 300, Developer Tools Kickoff, 2011, 00:47:49
But that’s totally crazy, amirite? Just for starters:
- It probably flies in the face of your entire career of experiencing the performance impact of GCed languages on the desktop and server
- Windows Mobile, Android, MonoTouch, and the whole rest of them seem to be getting along fine with GC
So let’s take them in turn.
GC on mobile is not the same animal as GC on the desktop
I know what you’re thinking. You’ve been a Python developer for N years. It’s 2013. Garbage collection is a totally solved problem.
Here is the paper you were looking for. Turns out it’s not so solved: 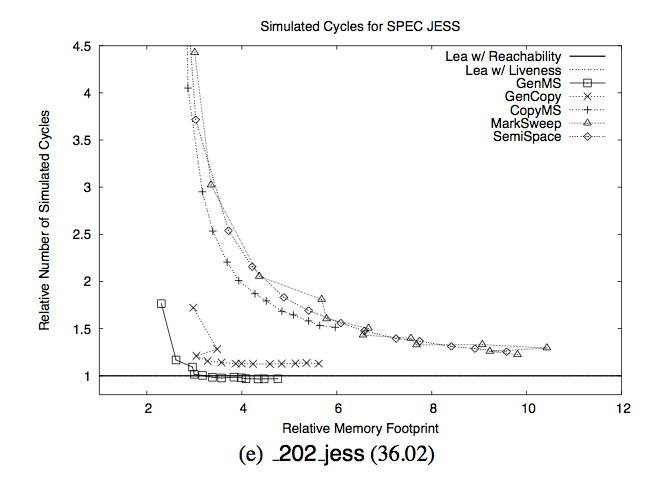
If you remember nothing else from this blog post, remember this chart. The Y axis is time spent collecting garbage. The X axis is “relative memory footprint”. Relative to what? Relative to the minimum amount of memory required.
What this chart says is “As long as you have about 6 times as much memory as you really need, you’re fine. But woe betide you if you have less than 4x the required memory.” But don’t take my word for it:
In particular, when garbage collection has five times as much memory as required, its runtime performance matches or slightly exceeds that of explicit memory management. However, garbage collection’s performance degrades substantially when it must use smaller heaps. With three times as much memory, it runs 17% slower on average, and with twice as much memory, it runs 70% slower. Garbage collection also is more susceptible to paging when physical memory is scarce. In such conditions, all of the garbage collectors we examine here suffer order-of-magnitude performance penalties relative to explicit memory management.
Now let’s compare with explicit memory management strategies:
These graphs show that, for reasonable ranges of available memory (but not enough to hold the entire application), both explicit memory managers substantially outperform all of the garbage collectors. For instance, pseudoJBB running with 63MB of available memory and the Lea allocator completes in 25 seconds. With the same amount of available memory and using GenMS, it takes more than ten times longer to complete (255 seconds). We see similar trends across the benchmark suite. The most pronounced case is 213 javac: at 36MB with the Lea allocator, total execution time is 14 seconds, while with GenMS, total execution time is 211 seconds, over a 15-fold increase.
The ground truth is that in a memory constrained environment garbage collection performance degrades exponentially. If you write Python or Ruby or JS that runs on desktop computers, it’s possible that your entire experience is in the right hand of the chart, and you can go your whole life without ever experiencing a slow garbage collector. Spend some time on the left side of the chart and see what the rest of us deal with.
How much memory is available on iOS?
It’s hard to say exactly. The physical memory on the devices vary pretty considerably–from 512MB on the iPhone 4 up to 1GB on the iPhone 5. But a lot of that is reserved for the system, and still more of it is reserved for multitasking. Really the only way to find out is to try it under various conditions. Jan Ilavsky helpfully wrote a utility to do it, but it seems that nobody publishes any statistics. That changes today.
Now it’s important to do this under “normal” conditions (whatever that means), because if you do it from a fresh boot or back-to-back, you will get better results since you don’t have pages open in Safari and such. So I literally grabbed devices under the “real world” condition of lying around my apartment somewhere to run this benchmark.


You can click through to see the detailed results but essentially on the iPhone 4S, you start getting warned around 40MB and you get killed around 213MB. On the iPad 3, you get warned around 400MB and you get killed around 550MB. Of course, these are just my numbers–if your users are listening to music or running things in the background, you may have considerably less memory than you do in my results, but this is a start. This seems like a lot (213mb should be enough for everyone, right?) but as a practical matter it isn’t. For example, the iPhone 4S snaps photos at 3264×2448 resolution. That’s over 30 megabytes of bitmap data per photo. That’s a warning for having just two photos in memory and you get killed for having 7 photos in RAM. Oh, you were going to write a for loop that iterated over an album? Killed.
It’s important to emphasize too that as a practical matter you often have the same photo in memory multiple places. For example, if you are taking a photo, you have 1) The camera screen that shows you what the camera sees, 2) the photo that the camera actually took, 3) the buffer that you’re trying to fill with compressed JPEG data to write to disk, 4) the version of the photo that you’re preparing for display in the next screen, and 5) the version of the photo that you’re uploading to some server.
At some point it will occur to you that keeping 30MB buffers open to display a photo thumbnail is a really bad idea, so you will introduce 6) the buffer that is going to hold a smaller photo suitable for display in the next screen, 7) the buffer that resizes the photo in the background because it is too slow to do it in the foreground. And then you will discover that you really need five different sizes, and thus begins the slow descent into madness. It’s not uncommon to hit memory limits dealing just with a single photograph in a real-world application. But don’t take my word for it:
The worst thing that you can do as far as your memory footprint is to cache images in memory. When an image is drawn into a bitmap context or displayed to a screen, we actually have to decode that image into a bitmap. That bitmap is 4 bytes per pixel, no matter how big the original image was. And as soon as we’ve decoded it once, that bitmap is attached to the image object, and will then persist for the lifetime of the object. So if you’re putting images into a cache, and they ever get displayed, you’re now holding onto that entire bitmap until you release it. So never put UIImages or CGImages into a cache, unless you have a very clear (and hopefully very short-term) reason for doing so. – Session 318, iOS Performance In Depth, 2011
Don’t even take his word for it! The amount of memory you allocate yourself is just the tip of the iceberg. No honest, here’s the actual iceberg slide from Apple. Session 242, iOS App Performance – Memory, 2012:

And you’re burning the candle from both ends. Not only is it much harder to deal with photos if you have 213MB of usable RAM than it is on a desktop. But there is also a lot more demand to write photo-processing applications, because your desktop does not have a great camera attached to it that fits in your pocket.
Let’s take another example. On the iPad 3, you are driving a display that probably has more pixels in it than the display on your desktop (it’s between 2K and 4K resolution, in the ballpark with pro cinema). Each frame that you show on that display is a 12MB bitmap. If you’re going to be a good memory citizen you can store roughly 45 frames of uncompressed video or animation buffer in memory at a time, which is about 1.5 seconds at 30fps, or .75 seconds at the system’s 60Hz. Accidentally buffer a second of full-screen animation? App killed. And it’s worth pointing out, the latency of AirPlay is 2 seconds, so for any kind of media application, you are actually guaranteed to not have enough memory.
And we are in roughly the same situation here that we are in with the multiple copies of the photos. For example, Apple says that “Every UIView is backed with a CALayer and images as layer contents remain in memory as long as the CALayer stays in the hierarchy.” What this means, essentially, is that there can be many intermediate renderings–essentially copies–of your view hierarchy that are stored in memory.
And there are also things like clipping rects, and backing stores. It’s a remarkably efficient architecture as far as CPU time goes, but it achieves that performance essentially at the cost of gobbling as much memory as possible. iOS is not architected to be low-memory–it’s optimized to be fast. Which just doesn’t mix with garbage collection.
We are also in the same situation about burning the candle from both ends. Not only are you in an incredibly memory-constrained environment for doing animations. But there is also a huge demand to do super high-quality video and animation, because this awful, memory-constrained environment is literally the only form factor in which a consumer-class pro-cinema-resolution display can be purchased. If you want to write software that runs on a comparable display, you have to convince somebody to shell out $700 just for the monitor. Or, they could spend $500, and get an iPad, with the computer already built in.
Will we get more memory? (UPDATE)
Some smart people have said “OK, you talk a lot about how we won’t get faster CPUs. But we can get more memory, right? It happened on desktop.”
One problem with this theory is that with ARM the memory is on the processor itself. It’s called package on package. So the problems with getting more memory on ARM are actually very analogous to the problems of improving the CPU, because at the end of the day it boils down to the same thing: packing more transistors on the CPU package. Memory transistors are a little easier to work with, because they are uniform, so it’s not quite as hard. But it’s still hard.
If you look at iFixit’s picture of the A6, you see that at the moment almost 100% of the top silicon on the CPU die is memory. What this means is that to have more memory, you need either a process shrink or a bigger die. In fact, if you normalize for process size, the “die” gets bigger every time there’s a memory upgrade:
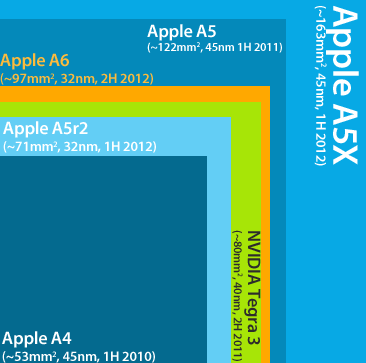
Silicon is an imperfect material, and bigger “good” pieces are exponentially expensive. They are also harder to keep cool and harder to fit in small devices. And they also have a lot of overlap with the problem of making better CPUs, because that is exactly what memory is: a top layer of CPU silicon that needs more transistors.
What I don’t know is why, in the face of these problems with PoP, manufacturers continue to use package-on-package delivery for system memory. I haven’t found an ARM engineer who can explain it to me yet. Perhaps one will show up in the comments. It may be that we could move away from PoP architecture and toward separate memory modules like you have in computers. But I suspect that it is not feasible, for the simple reason that breaking the memory into separate modules would almost certainly be cheaper to manufacture than bigger chips or process shrinks, yet every single manufacturer keeps doing process shrinks or bigger chips rather than moving memory modules off the die.
However, some smart engineers have e-mailed me to fill in some blanks.
An ex-Intel engineer:
As for PoP memory, it’s a huge boost for latency and eases routing concerns. But I’m not an ARM guy, can’t say if that’s the full story.
A robotics engineer:
When PoP memory will not be enough, “3D” memory will be able to “give enough memory for everybody” : chips of memory stacked together as they are manufactured, with possibility to place 10+ layers of 1GB RAM in the same volume as current hardware. But : cost will be higher, frequency or voltage will have to drop to stay in the power limit.
Mobile RAM bandwidth will not continue to increase as much as it did recently. Bandwidth is limited by the number of lines linking the SoC and the RAM package. Currently, most of the periphery of high performing SoC is used for RAM bus lines. The middle of SoC can’t be used to add RAM lines due to the way the packages are stacked. Next big improvement will come from single package highly integrated SoC & memory : SoC & memory will be engineered together and stacked in the same package, allowing for much smaller, denser and numerous RAM lines (more bandwidth), more freedom for SoC design and possibly lower RAM voltage. With this type of design, bigger caches may be a possibility as some RAM may be put in the SoC die with even higher bandwidth.
But then how does Mono/Android/Windows Mobile do it?
There are really two answers to this question. The first answer we can see from the chart. If you find yourself with 6 times as much memory as you need, garbage collection is actually going to be pretty fast. So for example, if you are writing a text editor, you might realistically be able to do everything you want in only 35MB, which is 1/6th the amount of memory before my iPhone 4S crashes. And you might write that text editor in Mono, see reasonable performance, and conclude from this exercise that garbage collectors are perfectly fine for this task, and you’d be right.
Yeah but Xamarin has flight simulators in the showcase! So clearly, the idea that garbage collectors are infeasible for larger apps flies in the face of real-life, large, garbage-collected mobile apps. Or does it?
What sort of problems do you have to overcome when developing/maintaining this game? “Performance has been a big issue and continues to be one of the biggest problems we have across platforms. The original Windows Phone devices were pretty slow and we had to spend a lot of time optimising the app to get a descent frame rate. Optimisations were done both on the flight sim code as well as the 3D engine. The biggest bottlenecks were garbage collection and the weaknesses of the GPU.”
Totally unprompted, the developers bring up garbage collection as the biggest bottleneck. When the people in your showcase are complaining, that would be a clue. But maybe Xamarin is an outlier. Let’s check in on the Android developers:
Now, keep in mind these are running my Galaxy Nexus — not a slow device by any stretch of the imagination. But check out the rendering times! While I was able to render these images in a couple of hundred milliseconds on my desktop, they were taking almost two orders of magnitude longer on the device! Over 6 seconds for the “inferno”? Crazy! … That’s 10-15 times the garbage collector would run to generate one image.
Another one:
If you want to process camera images on Android phones for real-time object recognition or content based Augmented Reality you probably heard about the Camera Preview Callback memory Issue. Each time your Java application gets a preview image from the system a new chunk of memory is allocated. When this memory chunk gets freed again by the Garbage Collector the system freezes for 100ms-200ms. This is especially bad if the system is under heavy load (I do object recognition on a phone – hooray it eats as much CPU power as possible). If you browse through Android’s 1.6 source code you realize that this is only because the wrapper (that protects us from the native stuff) allocates a new byte array each time a new frame is available. Build-in native code can, of course, avoid this issue.
Or, we can consult Stack Overflow:
I’m performance tuning interactive games in Java for the Android platform. Once in a while there is a hiccup in drawing and interaction for garbage collection. Usually it’s less than one tenth of a second, but sometimes it can be as large as 200ms on very slow devices… If I ever want trees or hashes in an inner loop I know that I need to be careful or even reimplement them instead of using the Java Collections framework since I can’t afford the extra garbage collection.
Here’s the “accepted answer”, 27 votes:
I’ve worked on Java mobile games… The best way to avoid GC’ing objects (which in turn shall trigger the GC at one point or another and shall kill your game’s perfs) is simply to avoid creating them in your main game loop in the first place. There’s no “clean” way to deal with this… Manual tracking of objects, sadly. This how it’s done on most current well-performing Java games that are out on mobile devices.
Let’s check in with Jon Perlow of Facebook:
GC is a huge performance problem for developing smooth android applications. At Facebook, one of the biggest performance problems we deal with is GCs pausing the UI thread. When dealing with lots of Bitmap data, GCs are frequent and hard to avoid. A single GC often results in dropped frames. Even if a GC only blocks the UI thread for a few milliseconds, it can significantly eat into the 16ms budget for rendering a frame.
Okay, let’s check in with a Microsoft MVP:
Normally your code will complete just fine within the 33.33 milliseconds, thereby maintaining a nice even 30FPS… However when the GC runs, it eats into that time. If you’ve kept the heap nice and simple …, the GC will run nice and fast and this likely won’t matter. But keeping a simple heap that the GC can run through quickly is a difficult programming task that requires a lot of planning and/or rewriting and even then isn’t fool proof (sometimes you just have a lot of stuff on the heap in a complex game with many assets). Much simpler, assuming you can do it, is to limit or even eliminate all allocations during gameplay.
With garbage collection, the winning move is not to play. A weaker form of this “the winning move is not to play” philosophy is embedded in the official Android documentation:
Object creation is never free. A generational garbage collector with per-thread allocation pools for temporary objects can make allocation cheaper, but allocating memory is always more expensive than not allocating memory. As you allocate more objects in your app, you will force a periodic garbage collection, creating little “hiccups” in the user experience. The concurrent garbage collector introduced in Android 2.3 helps, but unnecessary work should always be avoided. Thus, you should avoid creating object instances you don’t need to… Generally speaking, avoid creating short-term temporary objects if you can. Fewer objects created mean less-frequent garbage collection, which has a direct impact on user experience.
Still not convinced? Let’s ask an actual Garbage Collection engineer. Who writes garbage collectors. For mobile devices. For a living. You know, the person whose job it is to know this stuff.
However, with WP7 the capability of the device in terms of CPU and memory drastically increased. Games and large Silverlight applications started coming up which used close to 100mb of memory. As memory increases the number of references those many objects can have also increases exponentially. In the scheme explained above the GC has to traverse each and every object and their reference to mark them and later remove them via sweep. So the GC time also increases drastically and becomes a function of the net workingset of the application. This results in very large pauses in case of large XNA games and SL applications which finally manifests as long startup times (as GC runs during startup) or glitches during the game play/animation.
Still not convinced? Chrome has a benchmark that measures GC performance. Let’s see how it does…

That is a lot of GC pauses. Granted, this is a stress test–but still. You really want to wait a full second to render that frame? I think you’re nuts.
Look, that’s a lot of quotes, I’m not reading all that. Get to the point.
Here’s the point: memory management is hard on mobile. iOS has formed a culture around doing most things manually and trying to make the compiler do some of the easy parts. Android has formed a culture around improving a garbage collector that they try very hard not to use in practice. But either way, everybody spends a lot of time thinking about memory management when they write mobile applications. There’s just no substitute for thinking about memory. Like, a lot.
When JavaScript people or Ruby people or Python people hear “garbage collector”, they understand it to mean “silver bullet garbage collector.” They mean “garbage collector that frees me from thinking about managing memory.” But there’s no silver bullet on mobile devices. Everybody thinks about memory on mobile, whether they have a garbage collector or not. The only way to get “silver bullet” memory management is the same way we do it on the desktop–by having 10x more memory than your program really needs.
JavaScript’s whole design is based around not worrying about memory. Ask the Chromium developers:
is there any way to force the chrome js engine to do Garbage Collection? In general, no, by design.
The ECMAScript specification does not contain the word “allocation”, the only reference to “memory” essentially says that the entire subject is “host-defined”.
The ECMA 6 wiki has several pages of draft proposal that boil down to, and I am not kidding,
“the garbage collector MUST NOT collect any storage that then becomes needed to continue correct execution of the program… All objects which are not transitively strongly reachable from roots SHOULD eventually be collected, if needed to prevent the program execution from failing due to memory exhaustion.”
Yes, they actually are thinking about specifying this: a garbage collector should not collect things that it should not collect, but it should collect things it needs to collect. Welcome to tautology club. But perhaps more relevant to our purpose is this quote:
However, there is no spec of how much actual memory any individual object occupies, nor is there likely to be. Thus we never have any guarantee when any program may exhaust its actual raw memory allotment, so all lower bound expectations are not precisely observable.
In English: the philosophy of JavaScript (to the extent that it has any philosophy) is that you should not be able to observe what is going on in system memory, full stop. This is so unbelievably out of touch with how real people write mobile applications, I can’t even find the words to express it to you. I mean, in iOS world, we don’t believe in garbage collectors, and we think the Android guys are nuts. I suspect that the Android guys think the iOS guys are nuts for manual memory management. But you know what the two, cutthroat opposition camps can agree about? The JavaScript folks are really nuts. There is absolutely zero chance that you can write reasonable mobile code without worrying about what is going on in system memory, in some capacity. None. And so putting the whole question of SunSpider benchmarks and CPU-bound stuff fully aside, we arrive at the conclusion that JavaScript, at least as it stands today, is fundamentally opposed to the think-about-memory-philosophy that is absolutely required for mobile software development.
As long as people keep wanting to push mobile devices into these video and photo applications where desktops haven’t even been, and as long as mobile devices have a lot less memory to work with, the problem is just intractable. You need serious, formal memory management guarantees on mobile. And JavaScript, by design, refuses to provide them.
Suppose it did
Now you might say, “Okay. The JS guys are off in Desktop-land and are out of touch with mobile developers’ problems. But suppose they were convinced. Or, suppose somebody who actually was in touch with mobile developers’ problems forked the language. Is there something that can be done about it, in theory?”
I am not sure if it is solvable, but I can put some bounds on the problem. There is another group that has tried to fork a dynamic language to meet the needs of mobile developers–and it’s called RubyMotion.
So these are smart people, who know a lot about Ruby. And these Ruby people decided that garbage collection for their fork was A Bad Idea. (Hello GC advocates? Can you hear me?). So they have a thing that is a lot like ARC that they use instead, that they have sort of grafted on to the language. Turns out it doesn’t work:
Summary: lots of people are experiencing memory-related issues that are a result of RM-3 or possibly some other difficult-to-identify problem with RubyMotion’s memory management, and they’re coming forward and talking about them.
Ben Sheldon weighs in:
It’s not just you. I’m experiencing these memory-related types of crashes (like SIGSEGV and SIGBUS) with about 10-20% of users in production.
There’s some skepticism about whether the problem is tractable:
I raised the question about RM-3 on the recent Motion Meetup and Laurent/Watson both responded (Laurent on camera, Watson in IRC). Watson mentioned that RM-3 is the toughest bug to fix, and Laurent discussed how he tried a few approaches but was never happy with them. Both devs are smart and strong coders, so I take them at their word.
There’s some skepticism about whether the compiler can even solve it in theory:
For a long while, I believed blocks could simply be something handled specifically by the compiler, namely the contents of a block could be statically analyzed to determine if the block references variables outside of its scope. For all of those variables, I reasoned, the compiler could simply retain each of them upon block creation, and then release each of them upon block destruction. This would tie the lifetime of the variables to that of the block (not the ‘complete’ lifetime in some cases, of course). One problem: instance_eval. The contents of the block may or may not be used in a way you can expect ahead of time.
RubyMotion also has the opposite problem: it leaks memory. And maybe it has other problems. Nobody really knows if the crashes and leaks have 2 causes, or 200 causes. All we know is that people report both. A lot.
So anyway, here’s where we’re at: some of the best Ruby developers in the world have forked the language specifically for use on mobile devices, and they have designed a system that both crashes and leaks, which is the complete set of memory errors that you could possibly experience. So far they have not been able to do anything about it, although they have undoubtedly been trying very hard. Oh, and they are reporting that they “personally tried a few times to fix it, but wasn’t able to come with a good solution that would also perserve performance.”
I’m not saying forking JavaScript to get reasonable memory performance is impossible. I’m just saying there’s a lot of evidence that suggests the problem is really hard.
Update: A Rust contributor weighs in:
I’m a contributor to the Rust project, whose goal is zero-overhead memory safety. We support GC’d objects via “@-boxes” (the type declaration is “@T” for any type T), and one thing we have been struggling with recently is that GC touches everything in a language. If you want to support GC but not require it, you need to very carefully design your language to support zero-overhead non-GC’d pointers. It’s a very non-trivial problem, and I don’t think it can be solved by forking JS.
Okay but what about asm.js
asm.js is kind of interesting because it provides a JavaScript model that doesn’t, strictly speaking, rely on garbage collection. So in theory, with the right web browser, with the right APIs, it could be okay. The question is, “will we get the right browser?”
Mozilla is obviously sold on the concept, being the authors of the technology, and their implementation is landing later this year. Chrome’s reaction has been more mixed. It obviously competes with Google’s other proposals–Dart and PNaCl. There’s a bug open about it, but one of the V8 hackers doesn’t like it. With regard to the Apple camp, as best as I can tell, the WebKit folks are completely silent. IE? I wouldn’t get my hopes up.
Anyway, it’s not really clear why this is the One True Fixed JavaScript that will clearly beat all the competing proposals. In addition, if it did win–it really wouldn’t be JavaScript. After all, the whole reason it’s viable is that it potentially pries away that pesky garbage collector. Thus it could be viable with a C/C++ frontend, or some other manual-memory language. But it’s definitely not the same dynamic language we know and love today.
Slow relative to WHAT
One of the problems with these “X is slow” vs “X is not slow” articles is that nobody ever really states what their frame of reference is. If you’re a web developer, “slow” means something different than if you’re a high-performance cluster developer, means something different if you’re an embedded developer, etc. Now that we’ve been through the trenches and done the benchmarks, I can give you three frames of reference that are both useful and approximately correct.
If you are a web developer, think about the iPhone 4S Nitro as IE8, as it benchmarks in the same class. That gets you in the correct frame of mind to write code for it. JS should be used very sparingly, or you will face numerous platform-specific hacks to make it perform. Some apps will just not be cost-effective to write for it, even though it’s a popular browser.
If you are an x86 C/C++ developer, think about the iPhone 4S web development as a C environment that runs at 1/50th the speed of its desktop counterpart. Per the benchmarks, you incur a 10x performance penalty for being ARM, and another 5x performance penalty for being JavaScript. Now weigh the pros and cons of working in a non-JavaScript environment that is merely 10x slower than the desktop.
If you are a Java, Ruby, Python, C# developer, think about iPhone 4S web development in the following way. It’s a computer that runs 10x slower than you expect (since ARM) and performance degrades exponentially if your memory usage goes above 35MB at any point, because that is how garbage collectors behave on the platform. Also, you get killed if at any point you allocate 213MB. And nobody will give you any information about this at runtime “by design”. Oh, and people keep asking you to write high-memory photo-processing and video applications in this environment.
This is a really long article
So here’s what you should remember:
- Javascript is too slow for mobile app use in 2013 (e.g., for photo editing etc.).
- It’s slower than native code by about 5
- It’s comparable to IE8
- It’s slower than x86 C/C++ by about 50
- It’s slower than server-side Java/Ruby/Python/C# by a factor of about 10 if your program fits in 35MB, and it degrades exponentially from there
- The most viable path for it to get faster is by pushing the hardware to desktop-level performance. This might be viable long-term, but it’s looking like a pretty long wait.
- The language itself doesn’t seem to be getting faster these days, and people who are working on it are saying that with the current language and APIs, it will never be as fast as native code
- Garbage collection is exponentially bad in a memory-constrained environment. It is way, way worse than it is in desktop-class or server-class environments.
- Every competent mobile developer, whether they use a GCed environment or not, spends a great deal of time thinking about the memory performance of the target device
- JavaScript, as it currently exists, is fundamentally opposed to even allowing developers to think about the memory performance of the target device
- If they did change their minds and allowed developers to think about memory, experience suggests this is a technically hard problem.
- asm.js show some promise, but even if they win you will be using C/C++ or similar “backwards” language as a frontend, rather than something dynamic like JavaScript
Let’s raise the level of discourse
I have no doubt that I am about to receive a few hundred emails that quote one of these “bullet points” and disagree with them, without either reference to any of the actual longform evidence that I’ve provided–or really an appeal to any evidence at all, other than “one time I wrote a word processor and it was fine” or “some people I’ve never met wrote a flight simulator and have never e-mailed me personally to talk about their performance headaches.” I will delete those e-mails.
If we are going to make any progress on the mobile web, or on native apps, or really on anything at all–we need to have conversations that at least appear to have a plausible basis in facts of some kind–benchmarks, journals, quotes from compiler authors, whatever. There have been enough HN comments about “I wrote a web app one time and it was fine”. There has been enough bikeshedding about whether Facebook was right or wrong to choose HTML5 or native apps knowing what they would have known then what they could have known now.
The task that remains for us is to quantify specifically how both the mobile web and the native ecosystem can get better, and then, you know, do something about it. You know–what software developers do.
Thanks for making it all the way to the end of this article! If you enjoyed this read, you should follow me on Twitter (@drewcrawford), send me an email, subscribe via RSS, or leave a comment, and share my writing with your friends. It takes many, many hours to write and research this sort of article, and all I get in return are the kind words of my readers. I have many articles of similar depth at various stages of composition, and when I know that people enjoy them it motivates me to invest the time. Thanks for being such a great audience!
Want me to build your app / consult for your company / speak at your event? Good news! I'm an iOS developer for hire.
Like this post? Contribute to the coffee fund so I can write more like it.
Comments
Comments are closed.
 Tags
Tags 
- Subscribe via e-mail
Thank you for this article.
Fun fact: another language where there are talks of completely removing the GC is Rust, made by… Mozilla! (/rants/why-mobile-web-apps-are-slow/)
Thanks for your hard work on this. I am going to cry into a bucket now.
As a full-time frontend developer looking toward mobile development, I found this article extremely informative.
As much as I love Javascript, I know that every religion needs a Doubting Thomas. Thanks for the reality check.
Keep it up!
My personal suggestion is that, rather than asm.js, the browsers should accept LLVM IR. The big advantage this has is that there is already Emscripten offering an IR interface to the DOM, and secondly, there are already lots of language X -> LLVM IR implementations- particularly Clang, for example.
This has been an extremely informative read, and I really appreciate the effort and hard work that must have gone into writing this. Thanks a lot for such a great article!
Awesome article! I love your matter-of-fact style.
This is good. Thanks for such a comprehensive take.
>and meanwhile Intel is on track to do 22nm and maybe
>even 20nm just a little further out.
One issue though. You seem to be implying that Intel does not have 22 nm CPU yet. They actually have had several for over a year with the Ivy Bridge Core series. My 2012 MacBook Air has a 22 nm Core i7. The latest MacBook Airs have a Haswell Core CPUs also at 22 nm.
Other than what is probably just a mis-worded phrase. Great article.
You win the Internet! But – should we be cobbling up ways to run Lua in mobile browsers?
This looks like an interesting article, but it’s a bummer you chose to run SunSpider as your benchmark – that’s not a very cpu intensive benchmark. If you run Kraken or Octane, you’ll see that there’s been quite a bit of progress in VMs since 2008.
Please rename this to “The Best Article Ever Written On Mobile Web App Performance”
I am a Ruby programmer, so take that under advisement.
This is an awesome article, and well-written. I really enjoyed the tone.
Quick question – what if, say, every phone had 4-8GB of RAM? Would that change anything? It certainly seems that cramming that much RAM in a phone is a lot closer than 10-ish years away, but I have no idea the implications.
Great article, thanky for it !
Thanks for the article! It was certainly eye-opening. You’ve created something I can reference when asked how much slower is a mobile web app compared to native.
We’re in the middle of building mobile access to our online app. We’re stuck between building it quick and useable as a web app or spending around $10K to have it built right for Android and iOS. For now we’ve settled on building a mobile web app as a prototype and then building native apps as we get buy-in. So for us it makes sense to do both. We can iterate faster and get to market faster with a mobile web app. Once we lock down the functionality, then we can spend the hard money on native apps.
Cheers!
I havent’ finished reading your article, but I appreciated the level of readability and how you explain the fundamental issues without losing the reader. I think as JS becomes the lingua franca of the software world, we are going to see a lot of growing pains, and a lot of revelations that weren’t important when the JS community only consisted of people using it to change div backgrounds.
Excellent and insightful article. I learned a few things. Thank you!
Brilliant article, I’m a guilty party when it comes to engaging in pointless hand-wavy debates with friends on the whole native vs web debate; this brings a metric-ton of information and reasoning to the table. Thank you for your time and effort Drew!
I never really understood the adoration of Garbage Collection in the last decade. Small JS or PHP scripts are fine and not having to worry about memory management helps to put them together faster. But what I do not get is that some people actually choose to use a garbage collected language for larger projects, where performance and efficiency matters. I have worked on a larger C# application a couple of years ago and it was a terrible experience. GC is not a silver bullet – it may actually turn out to be a dead end in language design. For may own projects, I picked a non-managed language and I am very happy with that choice.
Great article, thanks for your time to get all this information in.
I have worked on some mobile apps made:
– entirely with JavaScript;
– made by combining custom shell, to connect JS with native and JS.
As those projects ware made at work I cannot disclose names or metrics. What I can say that on everything that I’ve worked we did memory profiling and we kept it under 20MB checking GC every time and ensuring it’s not called too often. Also another thing that I’ve used every draw should take less then 15ms.
For video/audio we had issues presented here and for those cases we used native.
My conclusion is that you can use JavaScript for mobile apps (not for intensive CPU/graphics) but without proper investigation, profiling, statistics the app will be slow.
When I did work on the PS2 with c++ there were no allocations during the render loop. GC or not, don’t allocate in your render loop.
I don’t completely agree with your assessment about GC for this reason. As long as you can control the GC and your allocations you should be okay.
Interesting article, but then, how do you explain something like Adobe AIR?
AIR produces performance, smooth, low-CPU apps that run on ARM7 and higher devices. And it does so with a JIT, a GC and unmanaged memory.
PicShop Pro (mine) and PhotoShop Touch are two examples of excellent AIR apps, running at 60fps.
I don’t think the real issue is inherent Javascript performance, it’s parasitic DOM loss.
Awesome. Thanks.
Image editing on smart phones does work reasonably well in JS, only because there are so few pixels. On the other hand, simple click and move or pen and move drawing on the desktop has been repeatedly broken in browsers like Chrome, as they move things haphazardly onto the GPU, causing noticeable lag. With minor exceptions, image editing apps simply fall flat within the W3C/JavaScript environment, whether on mobile or not. Flash is still the king in this area. Some of the modern CSS extensions do help quite a bit. It does seem like you glossed over CSS transitions and the like.
Oh man… so, I learned coding largely in GC languages – I did some C and C++, but not enough that I ever really grasped memory management…. and now, my professional life is taking me towards mobile development, and it looks like I am going to have a lot of learning to do.
Funny how technology steps backwards sometimes – if you’d asked me 8 years ago if I’d ever have to worry about memory management outside of 3d rendering, I’d have probably said no!
Anyway, I’m going to go quietly cry somewhere before beginning to read up on manual memory management.
You state “If your C program executes in 10ms, then a 50ms JavaScript program would be “near-C” speed. If your C program executes in 10 seconds, a 50-second JavaScript program, for most ordinary people would probably not be near-C speed.”
I think that most people would agree that this is the same difference in speed, (C would be 5x faster), so I would counter that if your app does runs like the first scenario, it is equally as slow as the second. No matter what scale you are on.
If these numbers you used are in fact real numbers, than I think that the fault lies in the verbiage, and we should stop comparing V8 to C.
Thank you for this article. I really appreciate your pragmatism.
@Shawn I think the article adequately explains Adobe AIR. We used AIR extensively, and selecting memory-optimal solutions is really important. So is minimizing GC-execution. Same story as other mobile developers.
AIR is capable of producing high performing mobile applications, but the GC and unmanaged memory are your enemies in this task, and they are not defeated without effort.
AS3 is also not a dynamic language (it can still use dynamic features, but good luck getting those to perform well), which changes things quite a bit.
This a very much needed, grown up article on the subject. I salute you for taking the time for writing, you, sir, are a gentleman and a scholar!
I wonder though if it would be maybe equally interesting to establish a metric around what people actually need / want to write? I have the impression that an awful lot of apps don’t go beyond the word processor complexity (if even that) and time is wasted on going native on all platforms under the sun.
Also, another interesting tangent is native extensions, what if you offload all the real intensive stuff to a worker in a separate thread which does all the heavy lifting in native world and comes back to the easy to write web based UI with the results? PhoneGap / Cordova is doing some of this, Firefox OS is probably doing an awful lot of this behind the scenes, otherwise there would be no way on Earth that a pure web stack OS could run with an acceptable performance on the kind of hardware it is selling on (we’re talking iPhone 3GS caliber).
Thanks. It’s hard to face the truth but I’m glad you uncovered it. Crossing my fingers that either:
1) Tooling gets better for pinpointing memory issues and developers learn to use these tools.
2) Memory resources drastically improve overnight.
Sounds like we need better tools as developers. Esp. in Mobile Safari.
Thanks for this – I gave a talk last year at C++Now ’12 about how C++ is too slow and not keeping up with modern hardware. If you watch the YouTube recording I demo editing a 680MP image on an iPad 3 (13:00 if you don’t want to bother with the bad audio) You don’t know how many times I hear “why didn’t you _just_ write it in JavaScript?”. If you want numbers regarding what I mean by C++ is slow – see the slides starting at 22:00 – it is that last slice of the machine that JavaScript divides by 50. , slide here .
@dain Your comment was particularly insightful. On the question of web app complexity, there is a weird feedback loop between what people use, what developers write, and what tools are built, that is sort of self-sustaining but not necessarily grounded in anything real. I have previously come out in favor of always writing complicated applications so I think this post probably reveals my negative bias toward simple software. To be clear, if you want to write really simple software, mobile JS could be a good option. It’s just not what I want to do with my life; I want to do things “not because they are easy, but because they are hard.”
On the question of bridging native/JS, in my view this is the single most important matter facing JS today. We need a cross-platform, reasonably-fast, GCed language that interfaces well with native code, and it would be super useful, and JS could totally be that with a little work. The trouble is whenever you say that, the purists start coming out of the woodwork telling you that you’re corrupting the language and detracting from the momentum to make JS fast by itself. So first you have to win the idea war that native bridging is necessary pragmatism and not language impurity.
Another important prerequisite to bridging JS and native is the security problem. JIT on some CPUs requires unprivileged code execution and so one of the things you really have to get right is making sure you don’t introduce security problems with native/JIT calling each other. WebKit2 is working seriously on this problem. As far as I’m aware they are the only developers who seem interested, which is troubling. If you want to make progress on the native bridge problem, pitching in with those guys is probably the best way to have an impact.
Thank you. This is one of the best technical articles I’ve ever read.
Brilliant article! Probably the best I’ve read this year. There’s nothing like testing assumptions and claims and trying to build a model that you can use for planning and further research. Many people are always telling us what is likely to happen in a given system but I find that testing those claims is quite revealing and necessary if you want to deploy good software.
In 2002 I was on a big project building scalable & reliable collaboration servers for a command and control system. For various context-specific reasons Java was the best choice and we ended up having to become JVM GC experts to get a system that was deployable. We were constantly throwing hardware at it, buying new machines a few times a year that had maximum ram, to get GC into something resembling a reasonable and responsive state. Even then we’d get into some nonlinear states of “silence” that you’d just have to ride out. We built our UIs with the idea of eventual consistency to help out, and used lots of caching all over the system to smooth the hiccups out. It was a lot of effort, and it is still running well today, so it paid off, but my intuition would have been to pick something well over the 6X memory you show here to have a well behaving GC system. But this article fits well with my decade of experience using GC’d systems.
Another thank you for your diligent work in covering the performance bottleneck that we find ourselves against.
It might be argued that as mobile devices gain more and more memory (most modern phones now have more than 900mb of memory) that the problem of GC will be mitigated. However as Apple took a stance on, should we simply accept using a GC as “the way and only way” the web platform should be built. As asm.js proves, perhaps there are other ways to build around the GC for high performing applications.
@ Andrew – Hmm. Well, it’s true that CPU usage, and memory are your enemies in AIR, but there’s a big difference between that, and saying that GC and JIT are the root of all evil.
To me, the article reads as if, these techniques are inherently unuseable on mobile. But AIR shows, that they are in fact, totally fine.
As for the dynamic language thing, well, you can use dynamic code all you like within AS3, without noticing any performance issues, as long as you’re not doing it inside an extremely performant piece of code.
I really don’t thing Javascript is the issue, it’s performance is basically on par with AS3, and AS3 is more then capable of producing everything but the most intensive apps.
The problem runs far far deeper than that I’m afraid. You could give Javascript native speeds tomorrow, and it wouldn’t change all that much. The DOM would still suck the lifeblood from that ARM processor in a heartbeat,
Thanks for the great article ! I work on CPU intensive x86 C++ applications and the claim that a sufficiently advanced JIT will make a managed language as fast as C/C++ always sound out of touch with me.
The problem for managed language is that native language compilers allow a variety of constructs and extensions that support performance. In actual application there can be a large gap (usually x2 to x8) between optimized vanilla native code and native code using a combination of assembly, SIMD intrinsics and compiler specific capabilities.
Moreover, most of performance improvements in these highly demanding workloads is very explicit. One cannot expect the compiler to do the best predictably without annotations, although there is cases where the compiler has excellent ideas.
In “C++ and Beyond 2011 – Why C++?”, Herb Sutter presented what he called the lost decade of programming world (1998-2008) when programmers and companies rushed into the managed world. Unfortunately, this did a lot of harm to software development. As time goes by more and more programmers realize that every cycle of cpu and every bit of memory matters, due to the move to mobile platform and therefore limited resources. Your article is the right follow-up on that matter.
I appreciate the effort you put in this article. Very good read indeed. Besides, I enjoyed your style of writing the most.
Thanks for sharing.
Love the multiple summaries.
JavaScript designers are nuts at least until memory becomes and after thought like it is on the desktop. Until that time, I’m counting my objects.
Typo: It’s “ECMAScript”, not “EMCA”
Nicely done!
Great article, amazingly well written. It’s really nice to read something that is backed up with research and citations.
Thought provoking for sure. Thanks!
In your section about garbage collection, and its deprecation on iOS, you claim “This [ARC] has nothing to do with the similarly-named garbage collection algorithm. [link to wikipedia page about Reference Counting]”
I’m not an Apple or iOS developer by any stretch, and the acronym “ARC” is not expanded anywhere in your article that I can find, but a quick web search indicates that in fact it stands for “Automatic Reference Counting”.
It seems to me highly implausible that “Automatic Reference Counting” would be unrelated to reference counting. Perhaps you could reword this to make your argument clearer.
Great article!
I noticed that quite a few commenters (here and at HN) are mentioning that future mobile devices will be have way more RAM (or already have; Galaxy 4 with 2 GB). It’s not as easy as that. As we all know, RAM needs power all the time and on mobile devices this shouldn’t be underestimated (http://www.nicta.com.au/pub?doc=3587).
So increasing RAM will always be a trade-off. And lets not forget that the processor and RAM should fit in the same chip.
TL;DR: The biggest problem are libraries and built-in functions trimmed for ease of use (“not designed for performance”) that copy tons and tons of data, cause GC pressure and some of the anti-GC examples are a little unfair, see Alex Gaynor’s talk.
You have a few good points regarding limites of JIT-ability of JS and language complexity but most of your comments on GC are a little biased. So yes, the asymptotical speed of dynamic vs static languages will always be off by a constant factor in terms of the language/compiler itself (2-10x probably). But I really don’t think GC and dynamic typing (requiring JIT compilation) are the main unsolvable problems of dynamic languages.
The main problem with dynamic languages is NOT GC. Alex Gaynor’s presentation on why dynamic langs are slow highlights (and some of your quotes mirror this) that most current dynamic languages are indeed “not designed for performance”. But not just the language itself, also especially libraries and built-in functions. Ease-of-use and safety over performance. Just take list-manipulation functions in C(++) vs Python. Speed is always a concern when working with the STL e.g., but does anyone even really know how Python lists are implemented internally? Dicts? Filter, map, sort, … all create copies of the original list in dynamic languages, not in most systems language libraries.
Some problems I have with your arguments:
Almost every dynamic language’s built-in functions and libraries are built on the premise of ease-of-use (no side-effects) over performance, compare e.g. filter on a Python dict vs a sensible C(++) library – former will allocate a new list, add elements to that, possibly reallocating several times in the process, latter will usually perform in-place deletion of elements. This constant realloc’ing copying leads to a lot of GC pressure.
Most programmers using dynamic languages just do not have the fundamental understanding of data-structures, memory management and “what’s happening inside your computer” as those working with static languages tend to have. Memory pressure is a huge performance bottleneck even on iOS without GC, just look around all the articles on mem optimizations.
Would an experienced programmer really ever alloc and dealloc objects inside the game’s main loop. I understand that GC “hides” some of these more subtle aspects from programmers but if you have a basic understanding of memory management you just don’t do it. With or without GC.
Real-time GC is possible (no long GC pauses and no problems skipping frames), at the expense of some performance – see recent advances .
ARC and manual memory management have their own problems. You could as well run into a second pause if you were to release a huge list (not an array). One can largely control when objects are deallocated by GC by how long one holds references, just like in manual memory management. Equally, misuse of ARC can lead to large allocations or deallocations inside a main loop. I am sure many novices leak memory in circular references but somehow static language communities require and teach more rigor.
Why is it that on devices up to iOS 3 (without GC) it was hard to have smooth-scrolling UITableViews? Advice was to use as few UIViews as possible and draw the cells into a single view, thus avoiding image caching, duplication, deallocation. Sounds just like Android. Handling images in memory-restricted environemts is just a pain, with or without GC. See Tweetie’s creator (http://web.archive.org/web/20100922230053/http://blog.atebits.com/2008/12/fast-scrolling-in-tweetie-with-uitableview/)
The reasons for removing GC from Rust do not primarily stem from the fact that it is slow – there’s a negative sentiment towards GC in “systems language” circles and GC prohibits writing some very low-level software (like kernels or drivers) well.
The way Android allocates and manages Bitmap buffers in Java is just generally borked, this has nothing to do with GC. Just not great design. If you had to use the same API from native code (which you don’t, thus the comments), you would run into similar issues. Yes, you’d be a few times faster but less than a magnitude).
I’d like to point out that Objective-C has its own overhead, since the dynamic languages are often compared against static languages like C, yet Objective-C is lumped in with static languages. Objective-C itself is 1.1-5x slower than C code due to the indirection of dynamic message dispatch and use of messages for property access in day-to-day code, probably not too far off from JIT’ed JavaScript. Something novices would not necessarily know unless there was a focus on speed in the obj-c community. First result I found indicates that NSArray is ~6x slower than C arrays, again, this is a library and convenience issue, has nothing to do with memory management directly. (http://www.memo.tv/nsarray-vs-c-array-performance-comparison-part-ii-makeobjectsperformselector/)
I don’t think John Gruber predicting it in September 2011 is all that impressive, when John Siracusa predicted Apple would add GC half-heartedly, and then drop it, all the way back in 2005.
And, as he explained, for instance, in this 2010 article — http://arstechnica.com/apple/2011/07/mac-os-x-10-7/10/#arc — the problem is not GC itself, but that ObjectiveC is particularly unsuited to it.
I think reading over what he had to say all the way back then can give a lot of perspective on what Apple’s story is.
So, having written GC (and PHP) programming for a decade, and now having to face the music of mobile, I have to ask: Why is mobile so memory constrained?
It’s not as though RAM is terribly power hungry. It’s not very expensive. RAM is very dense, it shouldn’t be any big deal to pack another GB or four of RAM into my phone…
So, why don’t they?
Amazing article.
The forefront of removing GC pauses is the “Azul” MMU supported no-pause collector for JVM. It has worst-case pause times shorter than C/C++ malloc/free — though with more cpu overhead.
Two other areas which you didn’t touch on, but are heavily related to differences between microbenchmarks and real-world tests in VM-vs-C are:
(1) cache-efficiency and structs… C, C++, ** and C# ** offer value-type structs and struct-arrays, both of which allow radically better cache efficiency for larger datasets when used correctly. Java, JS, and most other GC-VMs do not offer structs, which means even if CPU execution speed was equal, iterating over large datasets would have comparatively poor cache efficiency. — This is an effect not often seen in CPU speed microbenchmarks —
(2) Branch prediction and out-of-order issue on mobile CPUs is much more limited than on desktop CPUs. Early mobile ARM had no branch prediction or out-of-order-issue. Small microbenchmarks may not stress these limitations as much as real-world applications.
(2)
(2) branch-prediction
(3) Azul
Wow, very informative and mind blowing article
A small nit pick: it’s ECMAScript, not EMCAScript.